Alle Ergebnisse
Inhalt
Fakten
Hersteller
KFA2
Release
Anfang Februar 2025
Produkt
Grafikkarte
Preis
1.449 Euro (UVP)
Webseite
Media (21)
Galerie




















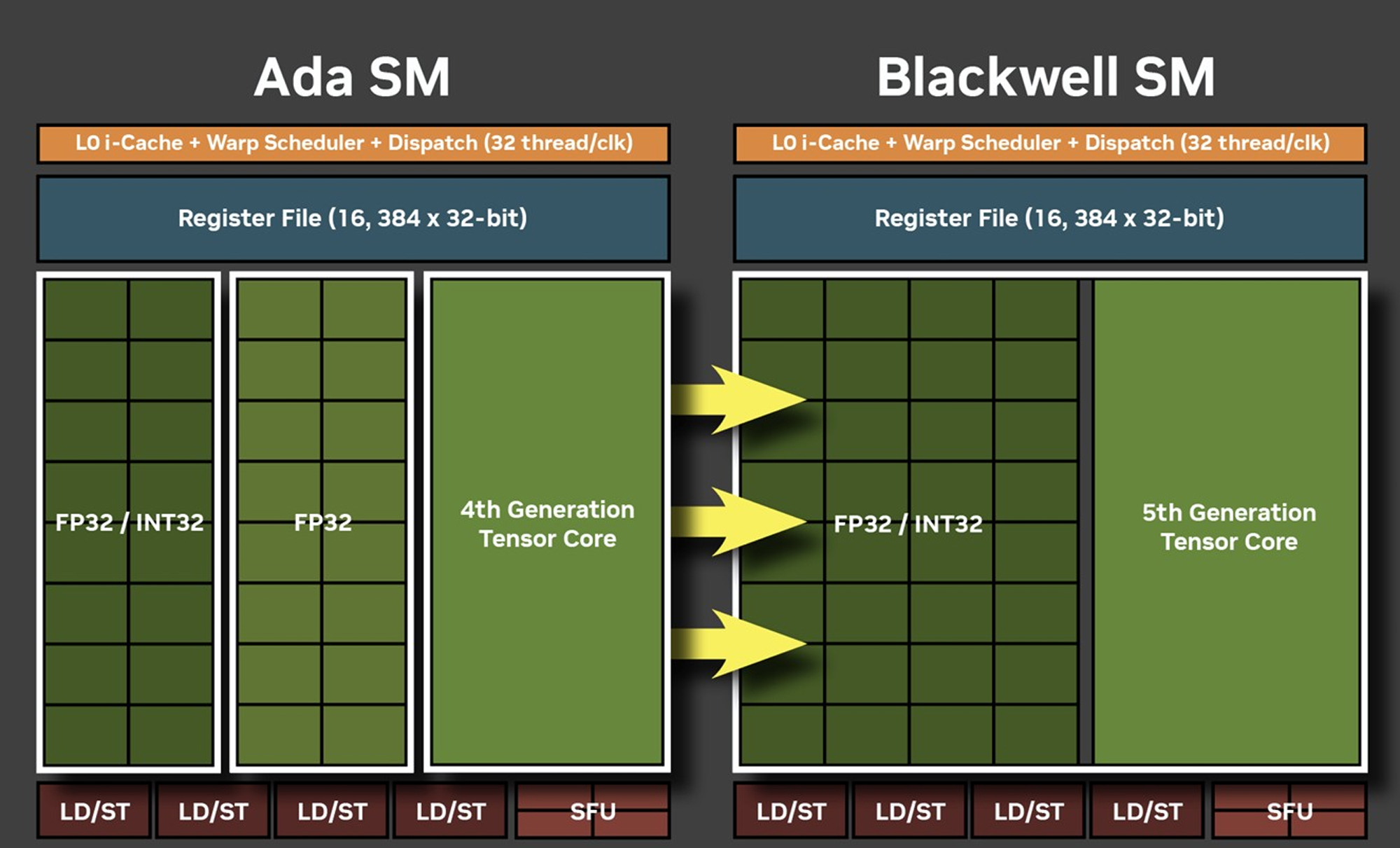 Das GB203-Silizium ist im Wesentlichen in der gleichen Komponentenhierarchie aufgebaut wie frühere Generationen von NVIDIA-GPUs, jedoch mit einigen bemerkenswerten Änderungen. Die GPU verfügt über eine PCI-Express 5.0 x16-Hostschnittstelle. PCIe Gen 5 gibt es seit Intels 12. Generation Core „Alder Lake“ und AMDs Ryzen 7000 „Zen 4“. Die GPU ist selbstverständlich mit älteren PCIe-Generationen kompatibel. Der GB203 verfügt außerdem über die neue GDDR7-Speicherschnittstelle, die mit dieser Generation ihr Debüt feiert. Der Chip verfügt über einen 256 Bit breiten Speicherbus, was der Hälfte der Busbreite des GB202 entspricht, der den RTX 5090 antreibt. NVIDIA nutzt diesen, um 16 GB Speicher mit 30 Gbit/s Geschwindigkeit anzutreiben, was eine Speicherbandbreite von 960 GB/s ergibt, was einer Steigerung von 34 % gegenüber dem RTX 4080 und seinem 22.5 Gbit/s GDDR6X entspricht.
Das GB203-Silizium ist im Wesentlichen in der gleichen Komponentenhierarchie aufgebaut wie frühere Generationen von NVIDIA-GPUs, jedoch mit einigen bemerkenswerten Änderungen. Die GPU verfügt über eine PCI-Express 5.0 x16-Hostschnittstelle. PCIe Gen 5 gibt es seit Intels 12. Generation Core „Alder Lake“ und AMDs Ryzen 7000 „Zen 4“. Die GPU ist selbstverständlich mit älteren PCIe-Generationen kompatibel. Der GB203 verfügt außerdem über die neue GDDR7-Speicherschnittstelle, die mit dieser Generation ihr Debüt feiert. Der Chip verfügt über einen 256 Bit breiten Speicherbus, was der Hälfte der Busbreite des GB202 entspricht, der den RTX 5090 antreibt. NVIDIA nutzt diesen, um 16 GB Speicher mit 30 Gbit/s Geschwindigkeit anzutreiben, was eine Speicherbandbreite von 960 GB/s ergibt, was einer Steigerung von 34 % gegenüber dem RTX 4080 und seinem 22.5 Gbit/s GDDR6X entspricht.
Inhalt
Ähnliche Artikel
Kommentar schreiben